Web3 without Blockchain
Web3 does not require Bitcoin, Ethereum, nor any other blockchain
It’s my prediction that Web3, the decentralized internet, will arrive. It will not involve blockchain accounting though. Decentralization has the wonderful property of being highly available and I think that is the killer feature. Blockchain technologies are something that will be forced to take less and less of a leading role as peoples desire for decentralized applications grows since it is the antithesis; slower than other databases, and requires high levels of connectivity to function.
The main problems with blockchain based technologies are throughput and cost. By their nature blockchains are slow; only a limited number of transactions can be processed each second. As the size of the userbase grows the wait to completion for transactions increases. Blockchains are also expensive; forward looking market dynamics prop up the cost of transactions beyond their intrinsic value. The actual cost of compute is pretty low. Given a fixed cost for a physical computer, compute just requires electricity. Renting machines in the cloud is more expensive, but still much cheaper than blockchain solutions.
The core desire for Web3 is to have organizations (‘decentralized autonomous organizations’ or DAOs) and applications which do not have central authorities. This lets anyone participate and prevents dissidents from being removed from platforms due to political, legal, or moral reasons. I don’t think the lack of removability is a great thing, but I will leave that debate to people who have thought about this more than myself. I will however note that, much like in Ursula Le Guin’s The Dispossessed, society as a whole can still choose to shun those they find unsavory.
The above goal is also the extreme example. Decentralized applications can also be used as “local-first software” which is a concept that has users keep their data on their local devices. Updates can be pushed out to cloud services or shared directly with other users, but this is not required. An example today is email clients. Your phone (or similar computing device) downloads the latest emails. At your leisure, even without internet connectivity, you can review those emails. You can write responses which will be sent when you have internet connectivity in the future. Solving for the extreme goal will also make this one possible to solve for, so the extreme goal is the one to focus on.
No Gods or Kings, only Cryptography
With the extreme goal of no central authorities in mind, what technical hurdles are there? In Cloud services storage and compute are the two key resources. Storage is the concept that there is some data with an identifier stored somewhere. Given that identifier it should be possible to retrieve it. Compute is the concept that inputs go into a function, processing happens, and outputs come out.
I will posit that storage is largely a solved problem. Technologies such as Bitorrent exist in the present day that allow for many people to host files, people lacking the file to request it, and then become hosts themselves. The InterPlanataryFileSystem (IPFS) moves beyond that to form what amounts to a global network. The more popular something is the more mirrored it can be. Incentive structures need to exist to ensure works are mirrored across multiple sites, but those are human details and this is an engineering approach I am trying to solve for.
Compute is where Web3 becomes more unsolved. Data needs to go in, be processed in some way, and provided as a clear representation. On top of that applications processing and displaying the data can operate. In the present day a Web3 solution may look like:
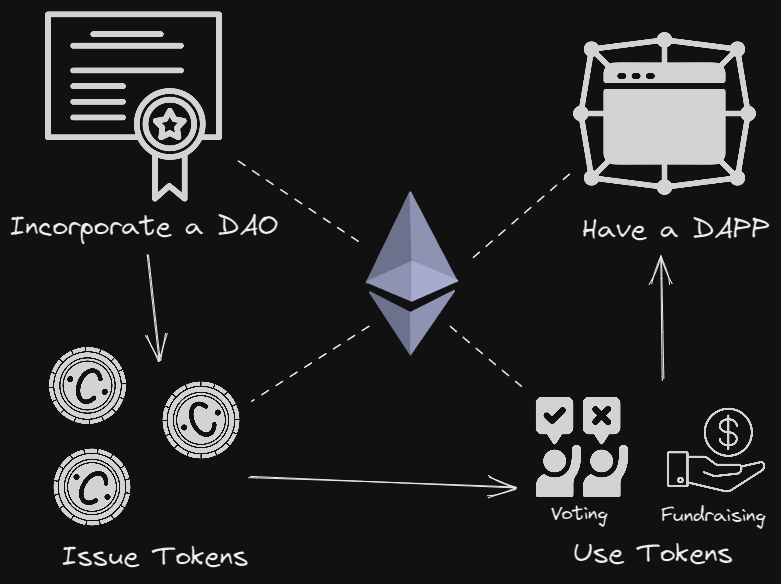
Lifecycle of a DAO and DAPP on Ethereum
- A DAO is formed and tokens issued on Ethereum.
- Tokens are sold for money and are used to perform compute activities / vote on matters in the DAO / gain fractional shares of income, etc
- An application is created and state is stored within the application:
- In a video game this may look like a players inventory or where they are in a game level
- In a social media application this may be a users IPFS media they uploaded and a set of other users media they have commented on. Currently application interactions suffer from the above problems of being slow and expensive. There is also a third issue in that the entire state of the blockchain, including other applications, must be stored. In order to process transactions for a social media app, you must also read and process transactions for your competitors social media apps, fintech apps, games, etc. Forming your own blockchain leads to other issues in that a small enough blockchain is vulnerable to a large enough attacker. If you can afford one server for your application and an attacker can afford two, your attacker is now in control of your application.
If the problem with compute can be solved, applications can be sped up, and Web3 can be more viable as a future. Following below I posit a way to speed up compute while remaining decentralized. The following technologies are used to do so:
- Decentralized Identifiers (DID): A scheme in which every entity can have one or more identifiers that represent their identity. These are decentralized in that the entity can choose who will attest to their identity. In the current day centralized identifiers are limited to things like “Sign in with Google/Apple/Facebook/Twitter”, etc. DID allows any entity to attest to an identity in a more free-form manner.
- Merkle Trees: Used in blockchains as well these allow for batching together multiple pieces of data under a single identifying hash. Merkle trees can have multiple levels, each one having its own identifying hash. Each hash serves to represent all data stored under that node.

Every entity (person, thing, even a place) can have one or more DIDs.
In this scheme everyone using Web3 has their own DID. Every person, IoT dohickey, pet, DAO, and application has their own DID. Entities can have more than one DID as well.
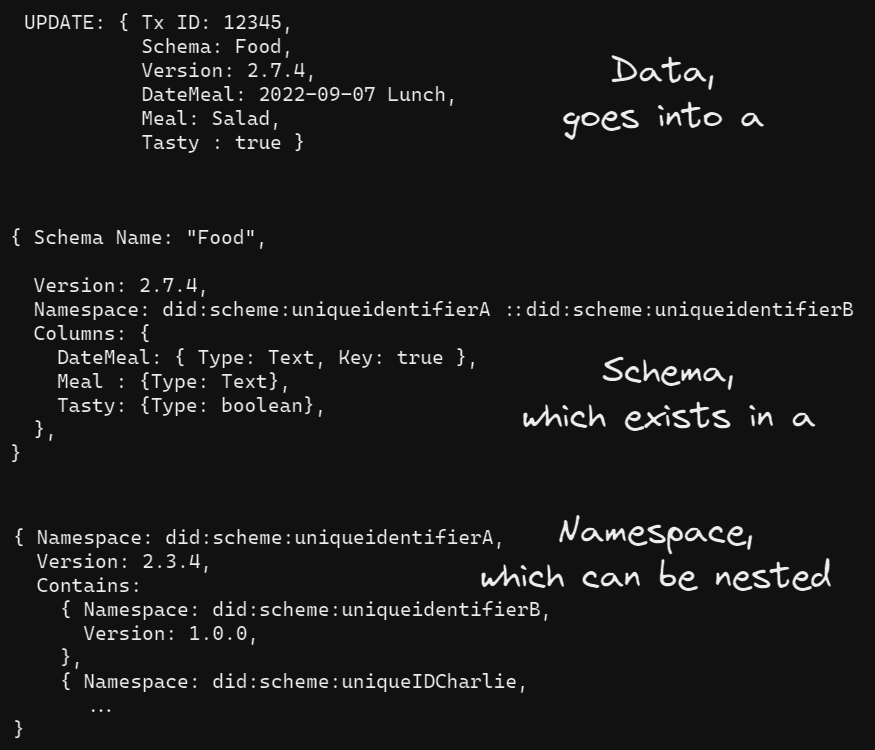
Data goes into Schemas, that force a version and constraints on the data. Schemas exist inside namespaces, tied to DIDs, to be possible to reference over time.
Each DID can publish schemas for data which they control. A schema describes the name and type of each variable. Additional information such as restrictions on values or descriptions of the variables use are possible as well. A schema is similar to a database schema. Schemas each have a name and version associated with them. Once a schema has been published it can have data published into the schema as well. Data is also versioned with each insertion, update, and deletion operation resulting in its own version. Data and Schemas can also be namespaced to form a set of items, with an implicit namespace for the top level DID. All data transformations are signed with a key registered in the DID so it can be verified to belong to the owner.
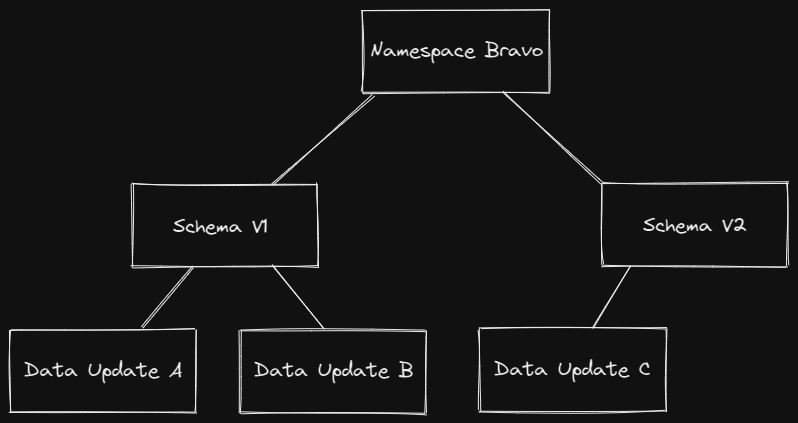
Tree of updates to versioned schemas to namespaces.
Data transformations, version changes to schemas, etc, can now be aggregated as elements of a merkle tree. Information not needed can just be referenced by the tree hash, while needed information can be requested and expanded out. This allows for performing operations over time such as requesting to see data at a particular time via something such as : Namespace XYZ, namespace version ABC inside that, data with transactions XYZ within that.
Every time that data is changed, that change is represented as a “transformation”. The transformation type applied is recorded as part of the transformation metadata. There are two types of transformation:
- 🔮Oracles: The oracle transformation is an opaque operation where the data transformation is applied with no information about the source of the data.
- 📰Published Versioned Algorithm (PVA): The PVA transformation is a transparent version of the transformation. A versioned algorithm, itself a type of versioned data, is referenced along with input arguments. The final output is the data transformation. By necesity there will almost always be oracle transformations. Inputting data for the first time, data from non-Web3 sources, etc, will be oracle operations. PVAs allow for performing complex operations in an open and verifiable manner. An example is providing a PVA to update data from one schema to another. In an ideal world oracle transformations would be used as little as possible to keep an application fully transparent. Some applications may derive their value from hidden state however, and make use of oracle updates to avoid revealing secret algorithms.
Propagating Changes
In order to sync data, clients can request the current Merkle root of the applications they are interested in. Clients can then compare that with their own merkle root and expand as needed to find the set of Merkle nodes they do not know about and sync those down. Clients do not need to sync down unrelated state, such as other applications, as would happen on more traditional blockchains. Providing up to date access to application compute state or storage could be a pay-as-you-go service in the future.
Clients can also submit their own data to applications. This would involve speaking to the application via an API to submit client signed data. The application would then choose how to handle it and publish updated data signed by both the application and the client.
It’s also possible to imagine a more “decentralized” solution where clients could just submit data transformations directly to an application without requiring the application to sign it itself. Such submissions would still need to be gated by an API, but would not require the application to sign off on it. This would improve the decentralized property, but at the cost of not allowing for easy moderation.
Pushing updates out through nodes
In order to propogate updates servers hosting a decentralized application would need to know other servers hosting the application and either push or pull the transformations as needed in order to keep everyone up to date. Security, the lack of changes on transformations, comes from both validating signatures for both the application and the client as well as making sure that the merkle roots from multiple servers agree. The latter option, multiple servers having the same root, is important to make sure that transactions are not being dropped. These are less strong guards than those that blockchain solutions impose and are in-fact more similar to x509 certificate transparency logs. It is my belief that these are sufficient for most uses. Anything that requires absolute guarantees should probably have some form of real world legal contract associated with it.
The above solution is no doubt something that others have noddled on, and it does away with a lot of the basis of Web3 with regards to currency. Micropayments, complete lack of central control, complete prevention of changing past values, are all features of blockchain that I believe to be more trouble than they are worth due to technical and political issues. What I have tried to do is carve away some features and present something that is faster and usable in the present day.