We live today in a golden age of CVEs. Never before have so many cybersecurity issues been so visible, documented, and available to those that want them. The pickaxes, shovels, pans, and sieves for mining new CVEs are also becoming more prevalent and easier to use with each passing year. Any aspiring security researcher can grab their equipment and stake their claim on the first ripe piece of code they find.
What is a CVE?
Before getting into the current day, it’s worth backing up a few steps and understanding how we got to this point. Sure, there are these things called CVEs. They are presumably bad and a chart measuring the amount per year goes up and to the right. What are they and why does that matter?
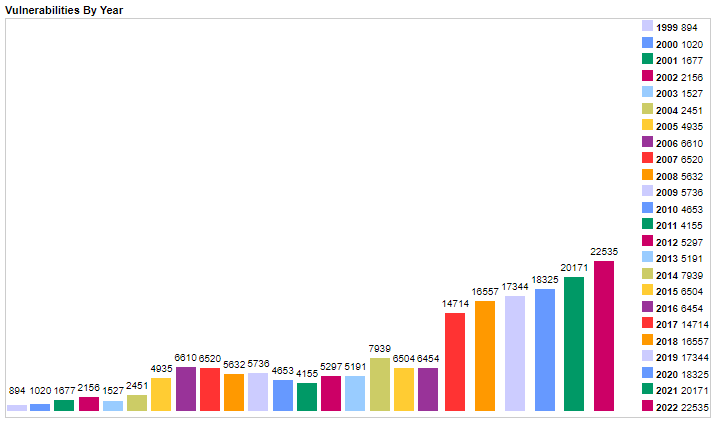
Chart showing the number of CVEs issued per year. One could draw a trend line, but it’s pretty clearly going up each year. Taken from https://www.cvedetails.com/browse-by-date.php.
CVE stands for Common Vulnerability and Exposure. These are colloquially known as “security bugs” or “vulnerabilities”. Every CVE has a unique number associated with it that allows for identifying it. Examples of CVE’s include CVE-2014-0160 and CVE-2017-5753. The first set of numbers is the year issued and the second a counter of issues for that year. CVEs are issued by the MITRE (pronounced “my-ter”, like the pope’s hat) Corporation, which is a very interesting group out of the scope of this article.
MITRE does not perform much in terms of vetting how bad a security vulnerability is nor even have a strong interest in knowing details about the issue. MITRE does however provide a definition of a vulnerability. A vulnerability is defined (source) as “A flaw in a software, firmware, hardware, or service component resulting from a weakness that can be exploited, causing a negative impact to the confidentiality, integrity, or availability of an impacted component or components”. With that in mind, what then are confidentiality, integrity, and availability?
Confidentiality is the ability for restricted information to only be viewed by an authorized party. When sending credit card numbers over the internet, confidentiality is the property which keeps those numbers from being seen by everyone along the way. Confidentiality also applies to data at rest. Unless you are authorized to, you probably don’t know what most of your coworkers make or their medical histories.
Integrity covers the ability to modify data. Going back to an example in confidentiality, your medical records can only be changed by authorized people such as your doctor or a nurse during your visit. Integrity also applies to data being transmitted, such as over the internet. It’s a separate property from confidentiality because even if the contents of a message are not, it can still be changed.
Availability determines if something, such as a program or a cloud service, can be used. Back to medical records, if the computer holding them is disconnected, the medical records have lost availability. If two people are communicating over a radio and the signal is jammed, the signal has lost availability.
Picture showing medical records and the potential negative impacts to them.
The impact of these issues, as well as how hard it is to carry out an attack, is summed up in a measurement called the Common Vulnerability Scoring System, or CVSS for short. This ranges from 0 - 10, with 10 being the worst. There is also a CVSS vector, which briefly describes the values that go into the score. Many organizations like to assign deadlines to how long a security issue can remain in a system, based on how high the score is.
Marketing of CVEs
Marketing is a controversial topic among software engineers. So many ads cite cutting edge this, innovative that. There are many SWEs who would say that good products should stand on their own. Some famous people within the industry might be a tad blunt about it and say “The innovation the industry talks about so much is bullshit” (Linus Torvalds). However, the positive take on marketing is that it allows people who would otherwise not know about a product to discover it and learn about how it can help them. Marketing has also wormed it’s way into CVEs and the security world.
Starting roughly with the Heartbleed issue in 2014, a number of security vulnerabilities have been marketed towards others. Some high profile examples include Meltdown, and DROWN. My personal favorite is “😾😾😾”, which can be pronounced as “thrangycat” as in “three angry cats”. What’s worth noting is that all of the names and logos assigned to these are ways of delivering information about the vulnerability, outside of the CVE regime. Each of these issues was reported to MITRE, received a CVE ID, a CVSS score, and was tracked by it’s CVE ID.
The purpose of coming up with names, logos, and web pages to promote the security vulnerability is to make it more accessible to others. A conversation or message about “Are you vulnerable to CVE-2016-0800?” is not that memorable and would get lost in the noise of everything else going on. Asking “This DROWN attack seems pretty serious? Are we at risk of DROWNing?” is better able to get people’s attention. For truly risky issues marketing provided a positive factor in getting people’s attention. It also gave the tech press an easy on-ramp to cover high severity issues since headlines like “Are your vendors causing you to DROWN?” practically write themselves.
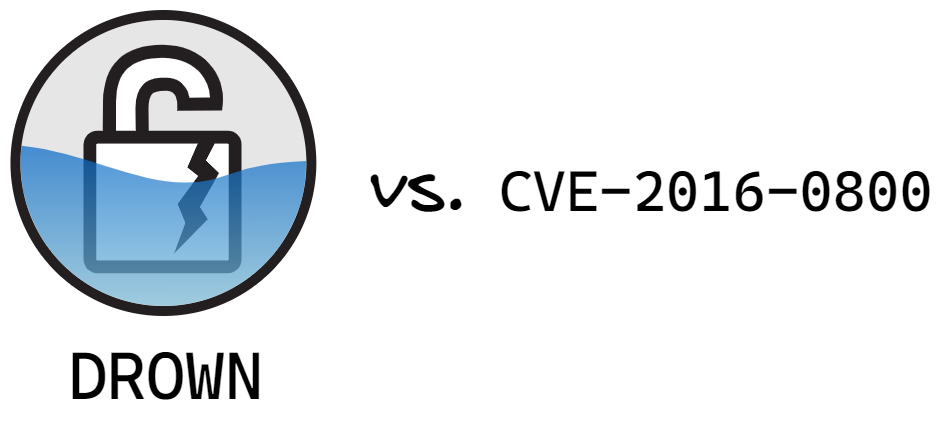
DROWN with it’s logo contrasted against the CVE. Which do you find more memorable?
The downside of the rise of CVE marketing is that it also gave a pathway for companies and people to advertise themselves. Heartbleed.com is registered and run by Synopsys, which sells CVE detection and remediation tools. 😾😾😾 is used to advertise how Red Balloon Security can help you discover and fix security issues. Other items may be created by individual security researchers to not only get the word out on the issue, but to also get the word out on who they are. Over time this can develop into a perverse incentive to try and market issues, even mild or non issues, because it helps market either yourself or your employer.
Discovery of CVEs
Marketing is only one of the reasons why so many more CVEs are being discovered and reported. Another major reason is that tools for discovering CVEs have become much more accessible and easy to use. Running static and dynamic analysis tools against products can quickly shake out the low hanging fruit of security vulnerabilities. As tools improve, the CVE fruit becomes lower and lower until you can just reach out and pluck some fresh CVEs off the tree.
Static Code Analysis
Static analysis of code covers what can be discovered without running code. There is an enormous amount of information that is possible to discover without even running something. By looking at compiled objects, or full images, one can discover:
- The set of installed binaries, scripts, and libraries. This is enough to cross-reference against CVE databases and find known issues.
- Saved values, such as strings. Strings with high entropy values (they look very random) or in specific formats (a string like “ghp_abcdefghijklmnopqrstuvwxyzABCD012345” can be recognized as a Github access token from the “ghp_” prefix) can be examined to see if they are secrets used for authentication or cryptography.
- Graphs of how functions interact with one another can be built and used to determine how a system interacts, without even running a single line of code.
- Linters, when run on source code, can uncover issues via examining the code. Problems such as reading uninitialized values, broken control flows, possible null pointer exceptions, and other issues are discoverable when using a linter.
It is truly exciting how much can be done in static code analysis without needing to run anything. Any of the above examples is enough to uncover serious issues in a piece of software and this is all possible without even running the software. More advanced researchers can use tools such as disassemblers to go into the details of how functions work and uncover issues that way.
Dynamic Code Analysis
Dynamic code analysis is a set of more advanced techniques to analyze running code. With dynamic code analysis the code to be examine is “instrumented” so that all of the interesting bits can be measured and analyzed as the code runs. One downside of this form of analysis is that it only covers what the code does when it is being examined, whereas static analysis covers everything that the code can possibly do. This is still able to yield powerful results.
The main purpose of dynamic analysis is to be able to find unintended behaviors in the running code. These include things like:
- Accessing data outside of an intended buffer.
- Using variables before their value has been set.
- Freeing memory twice.
- Race conditions in how different portions of the code interact with one another.
A special kind of dynamic analysis is fuzz testing. In fuzz testing a set of normal inputs are “mutated” by having their bits randomly changed to create an input that is just a little bit different from the original input. This mutated input is then fed into the program and the result is observed. Any unexpected behavior such as a crash or an issue listed above is treated as a success. Advanced fuzzers also monitor how changes to the input alter the flow of code and target the mutations for maximum effect.
Swords into Plowshares

Let Us Beat Swords Into Ploughshares by Evgeniy Vuchetich. Located outside of the United Nations in New York City.
they shall beat their swords into plowshares, and their spears into pruning hooks; - Isaiah 2:4 (excerpt)
The prior sections showed the varied and powerful weapons that attackers have available to them when discovering security vulnerabilities. I focus on the defensive end of security (“blue team” as it is sometimes called) and I am most interested in how I can effectively defend the software which I am responsible for.
The wonderful answer is that the swords can be beaten into plowshares. Nearly every tool discussed in the prior sections can be used during software development to discover and fix issues, often before the product even leaves development. This gives a path forward for blue teams to help their side build higher quality products. What’s more, the tools can all be integrated into continuous integration and build pipelines.
A typical strategy may be as follows:
- Linters and secret sniffers run over source code prior to merges. These items check for issues such as keys saved, or quality control issues with the code itself.
- The final built image is inspected to determine the set of final packaged items. This is becoming more popular and standard in the industry as a Software Bill of Materials, or “SBOM” for short.
- Call graphs for functions can also be built at the end of the build. Tooling for these is not as standardized and does not work as cleanly for tracing calls across files as SBOMs, at least at the time this article was written.
- During testing, dynamic analysis tools can be used when the test code is running. These tools will flag any issues found. When combined with test coverage tooling, it is possible to have a high level of confidence in issues being discovered.
- Finally, fuzz testing can be done as an extra testing step once all other tests pass. Fuzz testing works best when combined with coverage checking as well, to ensure that the input corpus results in reasonable coverage, in a reasonable amount of time.
Any issue the above tools find can be used to trigger failures in a build, or to hold a release until triaged and resolved. By implementing this strategy, defenders can be confident that the attackers will have all obvious venues closed off to them. A strong defense will prevent CVE numbers from going up, since the issues can be caught before release.
As an added benefit, detailed test coverage and fuzz testing will also help to improve the overall quality of the product, ensuring that as much code as possible is tested and that accidental malformed inputs are handled appropriately.
Summary
This article started with a discussion of CVEs and how more and more are getting discovered each year. From there it moved into what drives the discovery of CVEs. Building a reputation was one factor, but a far larger factor was the sheer number of tools developed at discovering CVEs. Finally, the article ends with a happy note: defenders can protect themselves with the same tools that attackers use.
As a postscript, I’d like to thank Ren Lee at https://pid.ren/ for inspiring me to write this up.