Load Balancing is an essential part of any scalable service. A single service, say a compute node which counts the number of vowels in a string, can only process so much data at one time. A developer can optimize the code, increase the CPU power, increase available RAM, but eventually limits will be hit.
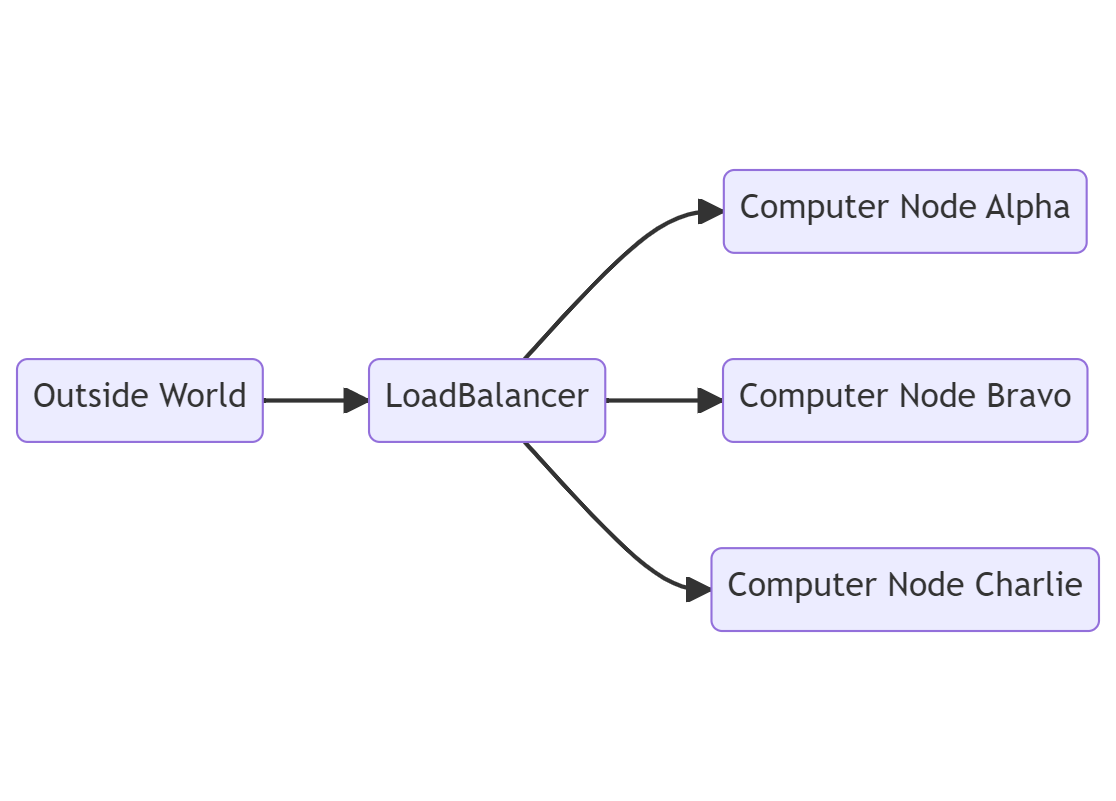
Diagram showing a Load Balancer and three possible compute nodes that traffic can flow to.
At the point that an additional node is created, there needs to be a way to decide where to send traffic. Is the traffic sent to each node, one after the other, in “round robin” fashion? Or is each node monitored to see how many free resources it has and the one with the most free resources gets the new inputs? Should clients with long running workloads be sent to the same node each time they connect? These are problems which a load balancer provides the solution to.
Most of the time a load balancer operates as the endpoint that a client connects to, with the compute nodes being opaque to the client. In HTTP APIs this would make the load balancer the HTTP endpoint the client connects to. This allows the load balancer to not only decide where a service request goes, but also make decisions based on the contents of that request. Going back to the earlier example of a vowel counting service the load balancer could examine the size of the request and assign workloads by keeping track of the total amount of characters each node is processing.
Zero trust networking (ZTN) changes this setup by breaking fundamental assumptions. In Zero trust networking, every connection must be encrypted. For the HTTP case this would look like HTTPS, which is HTTP over TLS. Another tenet of ZTN is that only the service that needs the data should see it. Intermediate services, such as a load balancer, should not be able to because that means the load balancer must now be as secure as the end service. If the load balancer is operated differently from the service or run by a different team, this becomes difficult to implement reliably and is a point of failure.
TLS Termination: To do or not to do? That is the Question.
When TLS becomes involved in a load balancer, crucial decisions have to be made. TLS operates by having the client and server, the opposite end points of a connection, establish a secure channel that others in the middle cannot listen in on.
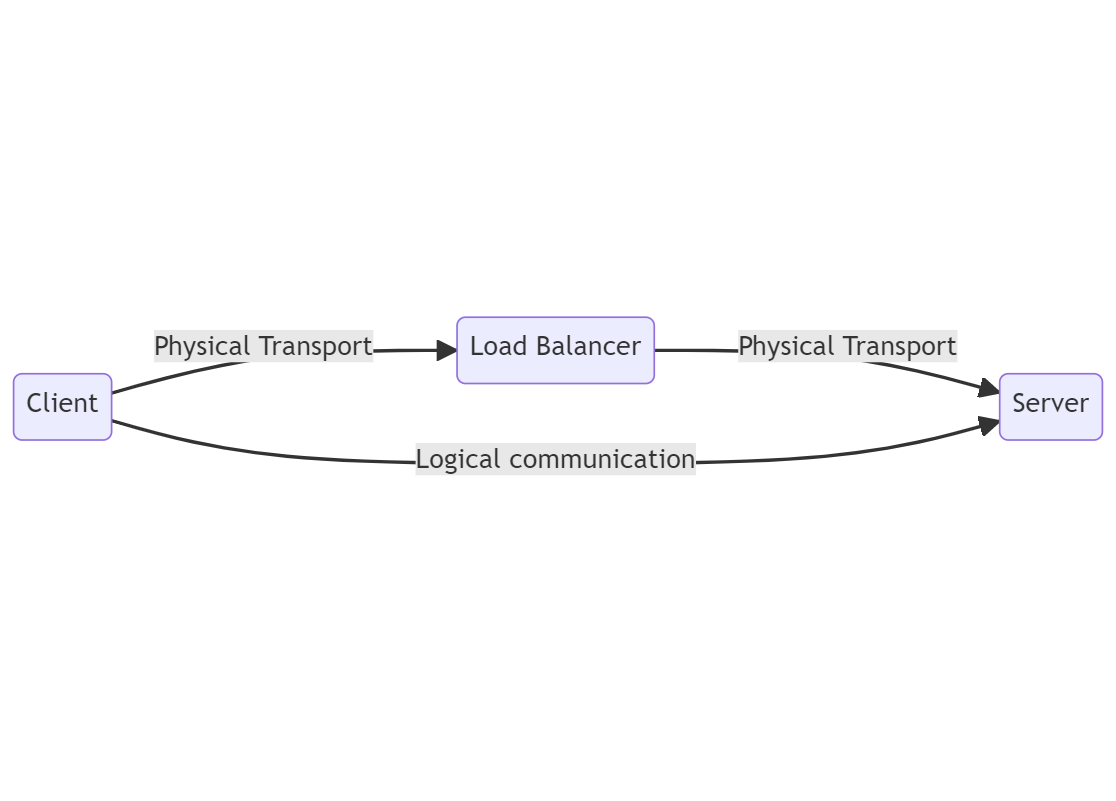
Picture showing a client to server TLS connection. The client transports data physically over a load balancer, but the load balancer may not be able to view that data.
A basic implementation of a load balancer has it act as an end point. Clients would connect to the load balancer and request to use a service. The load balancer would accept the requests, decide what node to send it to, then send the client back the reply. This clashes with ZTN because the load balancer must accept the connection, see what is being sent, then send that onwards to the end server. There may not be that much value in the load balancer seeing this data, for example credit card numbers, but the load balancer now has access to all this sensitive data.
Load balancers which support TLS connections and act as the endpoint clients connect to are said to perform “TLS Termination”. This is because they act as the endpoint (“terminating”) the TLS connection to fulfill their load balancing activities. Performing TLS termination has several advantages:
- Allows for performing load balancing based on the contents of the request.
- Can be used to upgrade legacy TLS, based on older protocols and algorithms now considered unsafe, from older clients.
- Saves end servers from needing to decrypt or manage TLS. What if, however, one doesn’t want the load balancer to terminate the connection?
The opposite of “TLS Termination” is “SSL Passthrough”[1]. With SSL Passthrough the load balancer does not have the ability to view the data being sent, it merely helps route that data to the end server. This fulfills the goals of ZTN by preventing the load balancer from being a place where an adversary could attack and steal the data being transported over it.
Turning to the OSI Model of network architecture, load balancers performing TLS termination operate at layer 7, the application layer. For a load balancer to function and not require TLS termination, it needs to function at layer 4, transport.
My focus for the rest of this article will be on layer 4 load balancing with SSL Passthrough. I think that performing TLS termination is generally a bad practice to follow because of the problem where it causes the load balancer to become just as important to secure as the end nodes working over the sensitive data. If the load balancer and the end nodes are run by different teams, or the load balancer is used to balance traffic across a number of different services, it becomes very easy to lose track of the importance of securing the load balancer. Therefore it becomes important to have load balancing solutions that function at layer 4.
Layer 4 Traffic Balancing
To successfully balance traffic at layer 4, both hardware and software need to be factored into the design. Each has it’s own advantages and can even function well on it’s own, for a period of time. By going with a hybrid hardware/software model one is able to achieve high resiliency in a load balancing design.
Please note that the below discussions are focusing on load balancing within a single site. Multi-site load balancing is more complex and not the focus of this discussion.
Network Router
Network routers and switches provide the physical transport over which data flows. There are a number of different ways to achieve this, which rely on assigning all of the end nodes the same IP address. Solutions involving Anycast and BGP over ECMP are covered below.
Anycast
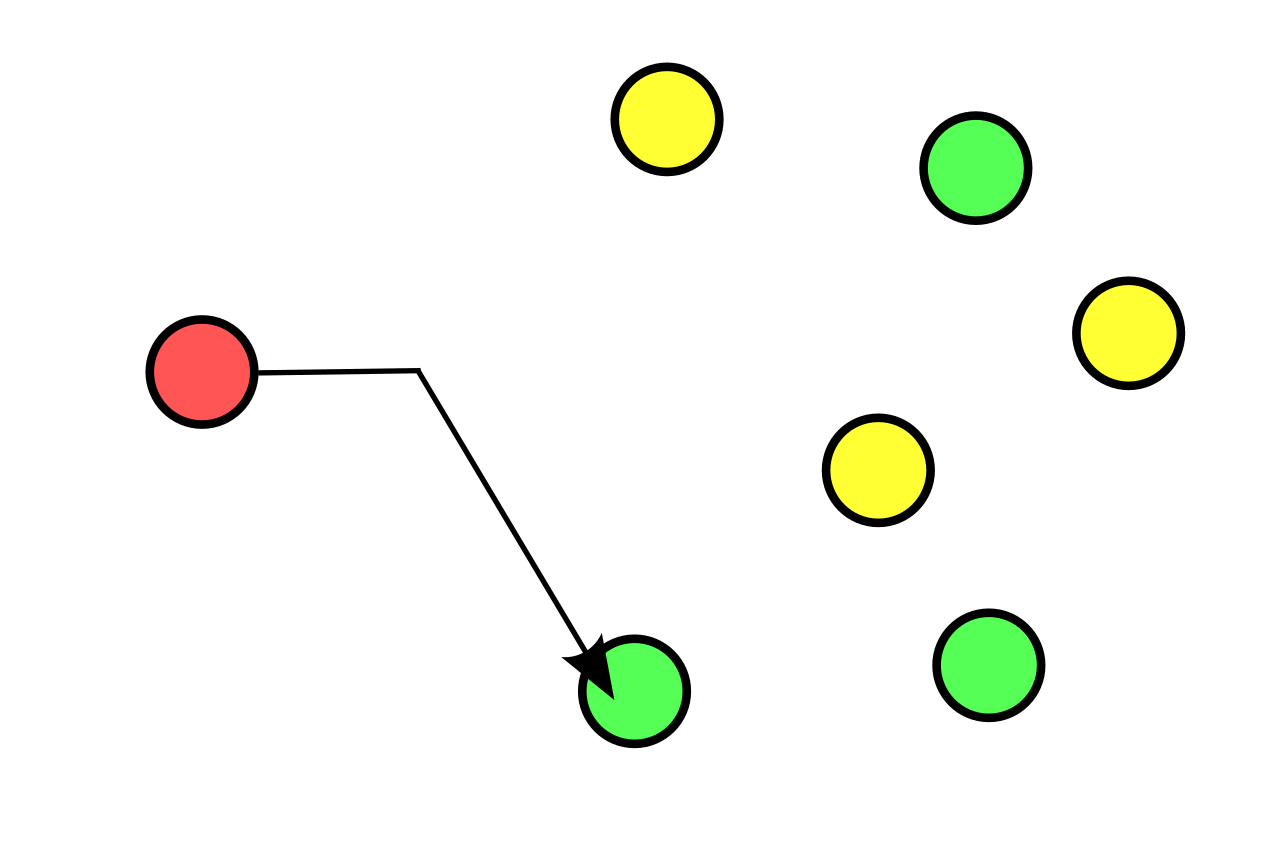
Picture showing a red client node forming an anycast connection to a green server node. Other possible end points are shown in green as well. Picture taken from Wikipedia: By Easyas12c~commonswiki - Wikimedia Commons, Public Domain, https://en.wikipedia.org/w/index.php?curid=53850281
Anycast IPs are a concept where specially designated IP addresses can go to any number of end hosts that have the same IP address. Routers many hops away from an anycast address are able to handle and route traffic the same as any other IP address. Routers closer to a destination do need to be anycast aware and make a decision on where to send the traffic.
There are a few drawbacks with anycast routing that prevent it from being more useful for load balancing situations. The first is that routing is generally stable and results in a client being directed to the closest (in terms of hops or other metrics) location. This means that multiple clients in one location will not be spread across end nodes without additional effort. The next drawback is that routers near the destination must be anycast aware to know how to route the traffic as it gets closer. Finally, anycast is only supported at a protocol level in IPv6. The next section covers how IPv4 deployments can implement an anycast style design using routing protocols.
BGP With ECMP
Border Gateway Protocol (BGP) with Equal-Cost Multi-Path (ECMP) routing is another solution that can implement having multiple endpoints referred to on one IP address. An advantage of this solution is that it will work on IPv4.
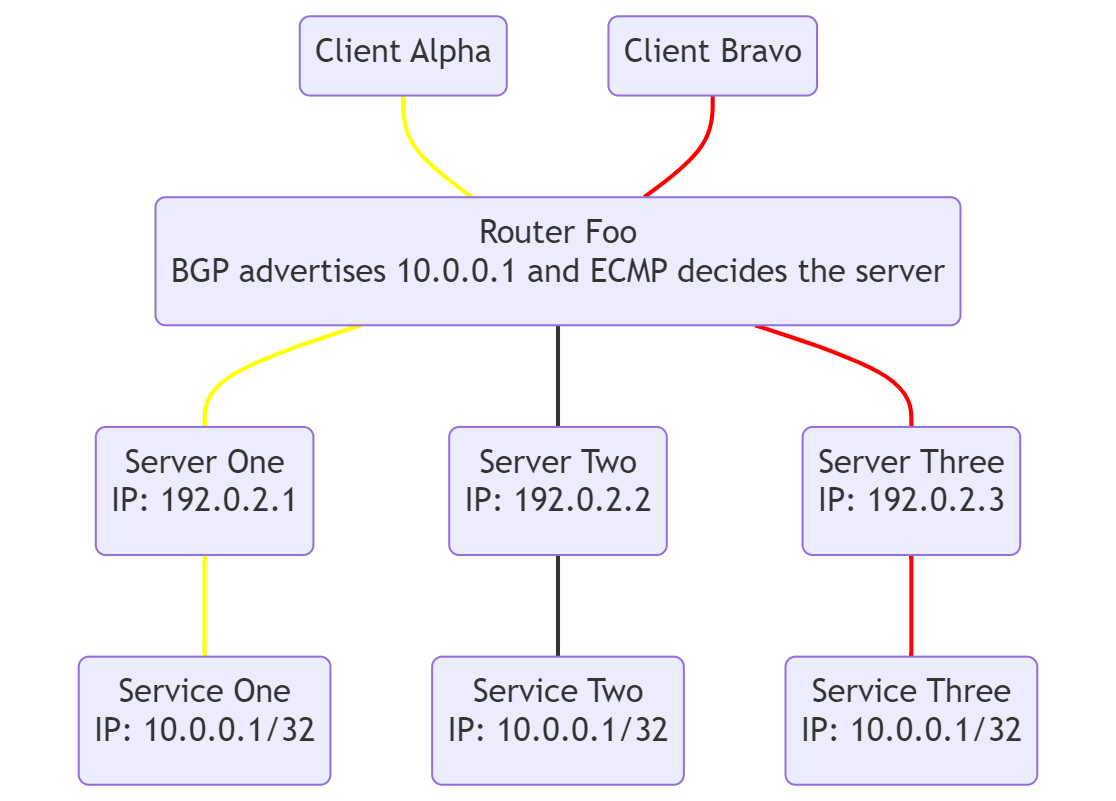
Diagram showing a network setup for load balancing across three servers in one site. Paths for clients flow is shown in yellow and red.
To set this up each service listens on the same IP address. In the above diagram this is represented via the loopback address of 10.0.0.1. The server each service is running on has it’s own individual IP address and they are all connected to a router, designated “Foo”.
BGP running on Foo injects the Virtual IP (VIP) of 10.0.0.1 as an advertised IP for clients to connect to. ECMP decides which server is followed to 10.0.0.1: From the perspective of ECMP the multiple services are all one end destination.
When a client, such as Alpha, connects to 10.0.0.1 via Foo, ECMP kicks in and looks at the “5-Tuple” that comprises the connection. This is:
- Client Alpha’s source IP
- Client Alpha’s source port
- The 10.0.0.1 destination IP
- The 10.0.0.1 destination port
- The protocol in use (TCP vs UDP) and uses the hash of this information to select the server to send traffic to. In the yellow path above that is Server One. Server One then sends the traffic to Service One where it is processed. Because this is stable as long as the 5-tuple does not change, this works for TCP connections that send multiple packets.
This doesn’t provide actual load balancing though. ECMP is a stateless routing strategy that doesn’t provide round robin routing. Attempts to balance traffic is done by assuming that the hash will evenly distribute traffic across the paths. If there is an imbalance the only knob one can twist is to change the hash and hope that the new one is more evenly distributed over time.
Other Hardware Solutions
The above solutions are not the only ones out there. There is an entire galaxy of possible hardware solutions, ranging from other protocols, the use of overlays, to specialized load balancing hardware. The ones which I mentioned are merely a couple common solutions that would not raise eyebrows if mentioned.
One hardware solution, which is related to a solution mentioned below, is HAProxy’s ALOHA Load Balancer. This is a solution which can be run on either a hardware appliance or as a VM and provides nice 🔔 and 😗🎶’s such as a graphical UI that make it easy to maintain over time.
Software
Software based load balancing is a solution that brings in it’s own tradeoffs. The pro’s of software load balancers is that they are cheaper and more configurable than comparable hardware options. The cheapness comes from being able to add new software instances for less cost than new instances of hardware. Configurability comes from software being much easier to add features to and adjust compared to hardware. For open source products, a truly dedicated power user could even add their own feature!
Another important feature of software based load balancers is that they are able to perform true load balancing, such as with a round robin strategy. This is due to them being stateful and able to track information such as: “I just handed off a new connection to Server Bravo, the next one will go to Charlie”. With server health information even more nuanced balancing can be performed.
A popular tool for performing Software load balancing with SSL Passthrough is HAProxy. This is a open-source tool which allows for various balancing solutions, rich logging, and many other useful features. The passthrough mode is set via mode tcp which forwards TCP connections. HAProxy can be used to perform additional checks, such as validating that the connection is TLS, but those are not required for a basic setup.
Unfortunately software is not a perfect solution. The biggest drawback of software load balancers is performance. They will always be slower than dedicated hardware and may require expertise and time to tune so they run well. Multiple software load balancers also need to account for the underlying network to allow them to be added and removed.
Hybrid
In a hybrid mode, both hardware and software solutions are brought together to minimize the downsides of individual solutions and benefit from the strengths. The downside of software load balancers is that the network needs to be aware of them to properly route traffic among multiple software nodes and allow for individual nodes to be removed as needed. So a basic implementation becomes:
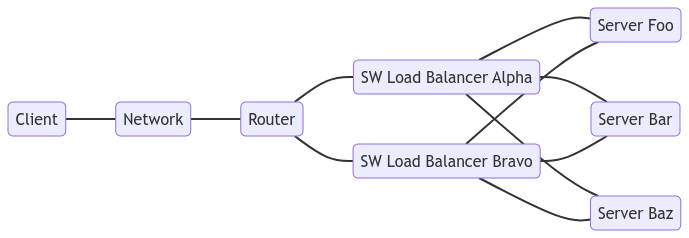
Diagram showing a router connected to SW Load Balancers. Each Load Balancer is connected to three servers.
Now either Alpha or Bravo can be removed for maintenance and the router updated to not attempt to route through them. The router may favor Alpha more than Bravo, but that is not an issue. More software load balancer nodes can be easily added, or the ECMP hash algorithm changed, if a subset of software balancers is receiving too much traffic.
But what if the router needs maintenance? Now the router has become a single point of failure. So more routers need to be added to allow for removing one.
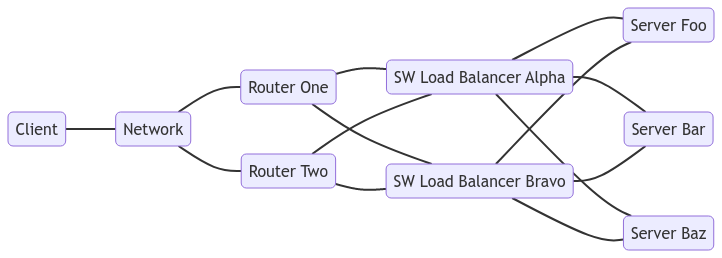
A diagram showing a setup with two routers that a network can access. Each router is connected to the two software load balancers. The software load balancers each remain connected to the three servers.
By adding a second router that can have traffic sent to it, either router can be used. This means that if one goes away traffic will flow to the remaining one. Now the routers no longer become a point of failure and can be added to distribute load or removed for maintenance. Does this mean that the network node above has a hidden load balancer and it is load balancing 🐢’s all the way down? Not at all: Router based solutions are based on advertising routes to the server IP addresses. Each router can do this on their own and other routers connected will choose the best seeming route, therefore there are no additional load balancers required.
Hybrid solutions are the most resilient ways to build out a load balancer. Being the most resilient is not always required though. If a service can handle some amount of downtime, a simple software load balancer may be all that is needed. Cloud only deployments may require their own abstractions to replace the router. The best solution to any problem requires balancing what is present with what is needed. By understanding all the different scenarios and edge cases an engineer is able to make the important decisions to design that best solution.
Conclusion
This post began with a problem of needing to load balance encrypted connections. From there tradeoffs of TLS Termination vs. SSL Passthrough were discussed and the author choose SSL Passthrough as the superior solution for Zero Trust Networking. Finally various ways of implementing this were shown where each solution had its tradeoffs. The best solution was then determined to be a hybrid hardware / software deployment.
Footnotes
- [1] The reason why “SSL” is used instead of “TLS” dates back to when this became a popular feature, i.e. when SSL was the name en vogue for this type of protocol. For whatever reason it seems to perform better in SEO than “TLS Passthrough”.
Special Thanks
Special thanks goes out to the following people who helped inspire this article as well as talk with me about the concepts. In alphabetical order, by last name: Jia Chen, Anthony Fok, Arthur Gautier.